Research
Dibya Ghosh, Marlos C. Machado, Nicolas Le Roux
NeurIPS 2020
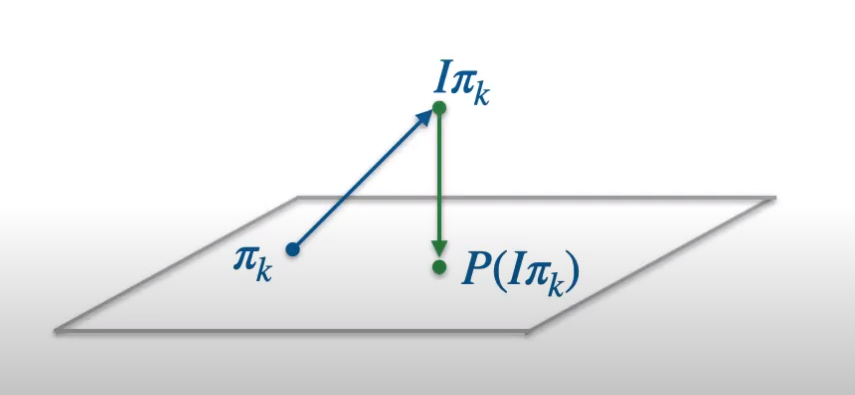
We reinterpret the classical REINFORCE algorithm as the iterated application of two operators: a policy improvement operator and a projection operator. This new perspective provides new insights about the behavior of policy gradient methods, and in particular, uncovers a strong link with their value-based counterparts.
Dibya Ghosh, Marc G. Bellemare
ICML 2020
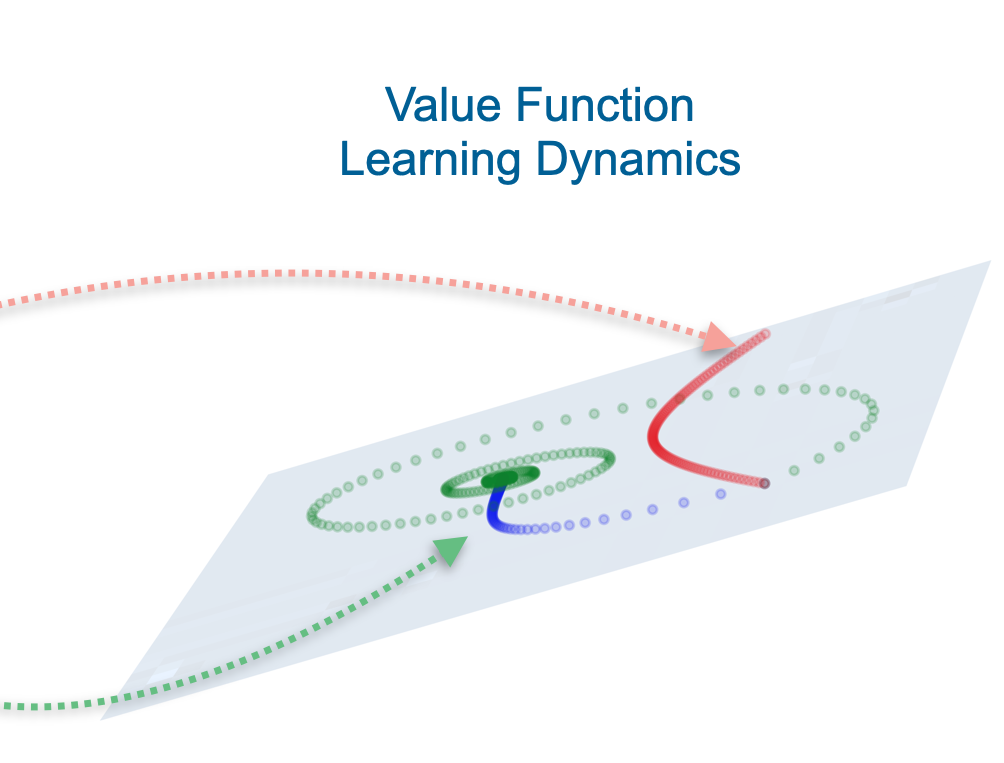
We study the learning dynamics of the classic off-policy value function learning algorithm, TD(0), through the lens of the state representation. Our work reveals several insights into how certain choices of state representation affect stability and divergence of RL.

Liam Fedus*, Dibya Ghosh*, John Martin, Yoshua Bengio, Marc G. Bellemare, Hugo Larochelle
NeurIPS Biological and Artificial RL Workshop 2019 (Oral)
We present the MEMENTO observation: that training a fresh agent which starts from the state that a trained agent plateaus can greatly improve performance. We show this manifests across a number of learning algorithms across all 60 games in the Atari Learning Environment. We demonstrate how this simple observation can induce a simple end-to-end agent which better avoids learning plateaus.
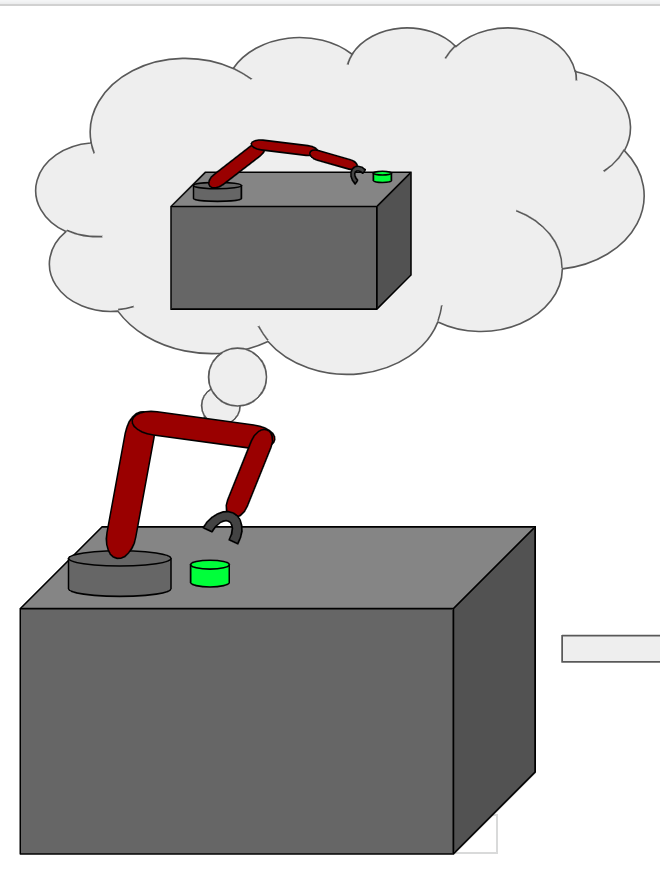
Dibya Ghosh*, Abhishek Gupta*, Justin Fu, Ashwin Reddy, Coline Devin, Benjamin Eysenbach, Sergey Levine
Preprint.
We present an algorithm (GCSL) which learns goal-reaching behaviors through iterative supervised learning. Drawing insights from imitation learning and hindsight experience replay, we show that a specific relabelling scheme for goals and actions induces a "dataset" of expert behavior. By using supervised learning, the algorithm avoids the optimization challenges present in value function methods and policy gradient schemes.

Dibya Ghosh, Abhishek Gupta, Sergey Levine
ICLR 2019
We present a representation learning algorithm (ARC) which attempts to optimize for functionally relevant elements of state. ARC relates distance between states in latent space with the actions required to reach the state, implicitly capturing system dynamics and ignoring uncontrollable factors. ARC is useful for exploration, features for policies, and for developing hierarchies.

Justin Fu*, Avi Singh*, Dibya Ghosh, Larry Yang, Sergey Levine
NeurIPS 2018
We present VICE, a method which generalizes inverse optimal control to learning reward functions from goal examples. By requiring only goal examples, and not demonstration trajectories, VICE is well suited for real-world robotics tasks, in which reward specification is difficult.
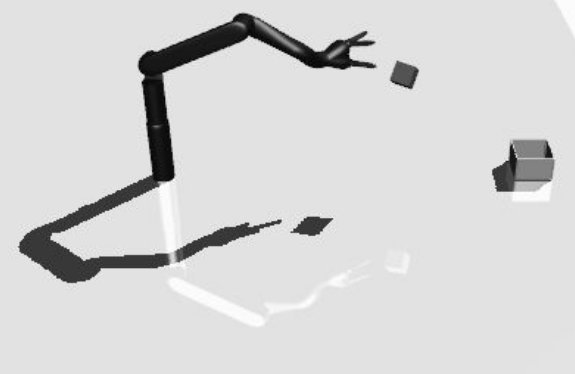
Dibya Ghosh, Avi Singh, Aravind Rajeswaran, Vikash Kumar, Sergey Levine
ICLR 2018.
We present a method for scaling model-free deep reinforcement learning methods to tasks with high stochasticity in initial state and task distributions. We demonstrate our method on a suite of challenging sparse-reward manipulation tasks that were unsolved by prior work.