Robotic Offline RL from Internet Videos via Value-Function Pre-Training
Summary
Video pre-training for robots (V-PTR) pre-trains by learning value functions on a large-scale video dataset like Ego4D, and continues refining learned visual features by performing offline RL on multi-task robot data like the Bridge dataset. This pre-training provides a useful initialization for fine-tuning on downstream robot tasks with improved generalization and robustness compared to other approaches.
Results
| Task | V-PTR (Ours) | R3M+BC | MVP+BC | VIP+CQL | VIPfrozen+CQL | PTR (CQL) | V-PTR w/o multi-task data |
|---|---|---|---|---|---|---|---|
| Croissant from bowl | 7 / 12 | 0 / 12 | 4 / 12 | 2 / 12 | 0 / 12 | 3 / 12 | 5 / 12 |
| Sweet potato on plate | 6 / 12 | 0 / 12 | 1 / 12 | 0 / 12 | 0 / 12 | 1 / 12 | 1 / 12 |
| Knife in pot | 6 / 12 | 0 / 12 | 0 / 12 | 0 / 12 | 0 / 12 | 0 / 12 | 0 / 12 |
| Total | 24 / 48 | 0 / 48 | 6 / 48 | 2 / 48 | 0 / 48 | 5 / 48 | 7 / 48 |
Task success rates of V-PTR and prior methods on several manipulation tasks over 12 trials (best-performing method indicated in red). Note that V-PTR outperforms all prior methods, including those approaches that do not fine-tune the learned representation, use imitation learning for downstream control, or do not incorporate video data.
| Task | V-PTR (Ours) | R3M+BC | MVP+BC | VIP+CQL | VIPfrozen+CQL | PTR (CQL) | V-PTR w/o multi-task data |
|---|---|---|---|---|---|---|---|
| Croissant from bowl | 8 / 12 | 0 / 12 | 3 / 12 | 2 / 12 | 0 / 12 | 0 / 12 | 3 / 12 |
| Sweet potato on plate | 4 / 12 | 0 / 12 | 2 / 12 | 0 / 12 | 0 / 12 | 1 / 12 | 2 / 12 |
| Knife in pot | 4 / 12 | 0 / 12 | 0 / 12 | 1 / 12 | 0 / 12 | 0 / 12 | 0 / 12 |
| Total | 20 / 48 | 0 / 48 | 5 / 48 | 4 / 48 | 0 / 48 | 1 / 48 | 6 / 48 |
Task success rates of V-PTR and prior methods on several manipulation tasks over 12 trials (best-performing method indicated in red). Note that systemname outperforms all prior methods, including those approaches that do not fine-tune the learned representation, use imitation learning for downstream control, or do not incorporate video data.
| V-PTR (Ours) | VIP | PTR | VIPreward | |
|---|---|---|---|---|
| Open Microwave | 5 / 12 | 2 / 12 | 0 / 12 | 0 / 12 |
| Sweep Beans | 6 / 12 | 5 / 12 | 2 / 12 | 2 / 12 |
Performance of V-PTR, VIP, and PTR on more complex tasks. V-PTR outperforms PTR as well as VIP variants that use downstream CQL or BC weighted by the reward shaping from Ma et al.
Analysis
 GradCam:
Grad-CAM visuals superimposed on frames from robot data. Regions highlighted in green denote patches of the image observation with the most significant influence on the learned policy. With no video pre-training (PTR), background areas in the image exert a significant influence on the output of the learned policy. In contrast, initializing the policy with the video pre-trained representation enables it to focus on gripper and object positions, which are crucial for solving the task.
GradCam:
Grad-CAM visuals superimposed on frames from robot data. Regions highlighted in green denote patches of the image observation with the most significant influence on the learned policy. With no video pre-training (PTR), background areas in the image exert a significant influence on the output of the learned policy. In contrast, initializing the policy with the video pre-trained representation enables it to focus on gripper and object positions, which are crucial for solving the task.
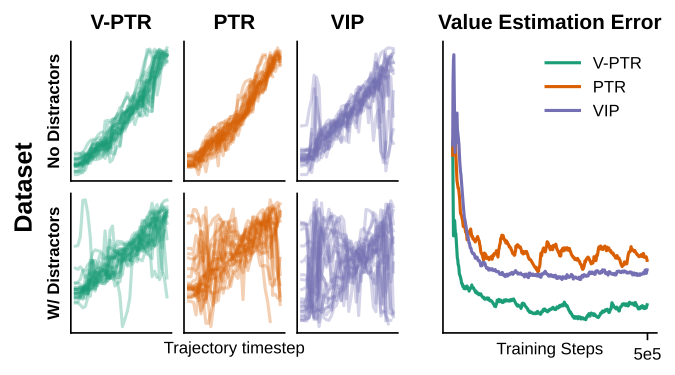 Value Visualization:
Our demonstrations were labeled with positive rewards at the end of each trajectory and negative rewards elsewhere. The correct value function should then trends upwards during the execution of the task. All methods are able to achieve this on the training data, but our method performs better than other methods when evaluated on a held-out dataset as well as when novel distractors are introduced.
Value Visualization:
Our demonstrations were labeled with positive rewards at the end of each trajectory and negative rewards elsewhere. The correct value function should then trends upwards during the execution of the task. All methods are able to achieve this on the training data, but our method performs better than other methods when evaluated on a held-out dataset as well as when novel distractors are introduced.
Setup
 Setup:
We used a toykitchen setup described in the Bridge dataset (Ebert et al. 2021)
for our experiments, which utilizes a 6-DoF WidowX 250 robot.
Setup:
We used a toykitchen setup described in the Bridge dataset (Ebert et al. 2021)
for our experiments, which utilizes a 6-DoF WidowX 250 robot.