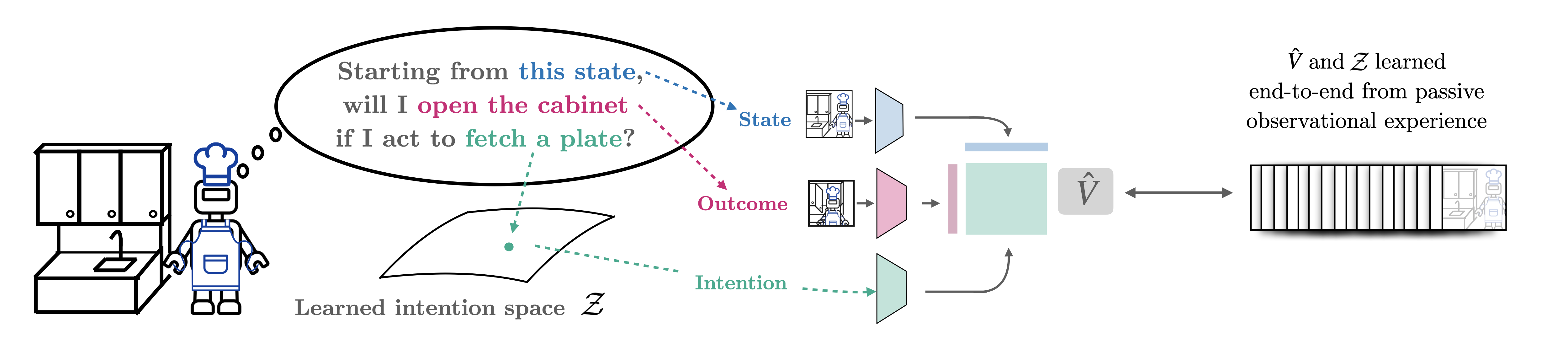
We pre-train on passive data (e.g. video data) to extract a general knowledge of how an agent may act to influence its environment. Our approach models the effects of acting with intention: estimates the likelihood of witnessing any given outcome in the future when acting according to achieve some other intention.
Abstract
Passive observational data, such as human videos, is abundant and rich in information, yet remains largely untapped by current RL methods. Perhaps surprisingly, we show that passive data, despite not having reward or action labels, can still be used to learn features that accelerate downstream RL. Our approach learns from passive data by modeling intentions: measuring how the likelihood of future outcomes change when the agent acts to achieve a particular task. We propose a temporal difference learning objective to learn about intentions, resulting in an algorithm similar to conventional RL, but which learns entirely from passive data. When optimizing this objective, our agent simultaneously learns representations of states, of policies, and of possible outcomes in an environment, all from raw observational data. Both theoretically and empirically, this scheme learns features amenable for value prediction for downstream tasks, and our experiments demonstrate the ability to learn from many forms of passive data, including cross-embodiment video data and YouTube videos.