Divide-and-Conquer Reinforcement Learning
Video
Standard model-free deep reinforcement learning (RL) algorithms sample a new initial state for each trial, allowing them to optimize policies that can perform well even in highly stochastic environments. However, problems that exhibit considerable initial state variation typically produce high-variance gradient estimates for model-free RL, making direct policy or value function optimization challenging. In this paper, we develop a novel algorithm that instead partitions the initial state space into "slices", and optimizes an ensemble of policies, each on a different slice. The ensemble is gradually unified into a single policy that can succeed on the whole state space. This approach, which we term divide-and-conquer RL, is able to solve complex tasks where conventional deep RL methods are ineffective. Our results show that divide-and-conquer RL greatly outperforms conventional policy gradient methods on challenging grasping, manipulation, and locomotion tasks, and exceeds the performance of a variety of prior methods.
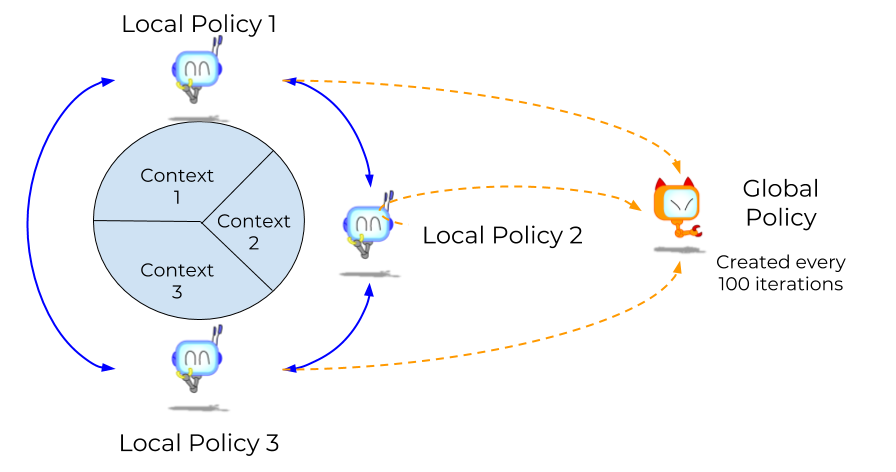
High Level Idea
For problems with high initial state variability, we partition the initial state space of the task into contexts using clustering algorithms. We train an ensemble of local policies, each specialized to a particular context. The objective for each policy is to maximize expected reward and minimize the KL divergence from each of the other policies in the ensemble. On a slower timescale, the ensemble is distilled together into a global policy, which can operate on the original task.
Paper

Citation
Dibya Ghosh, Avi Singh, Aravind Rajeswaran, Vikash Kumar, Sergey Levine
Divide-and-Conquer Reinforcement Learning In ICLR 2018.